在[Day 01]時就有提及,未來具有邊緣智能(Edge AI)的智慧物聯網(AIoT)裝置一定少不了單晶片(MCU)。而從[Day 03]更可看出目前市售支援tinyML的開發板可能有九成以上都是使用Arm Cortex-M系列的MCU,所以接下來要來幫大家好好介紹為什麼它會如此受歡迎且佔有這麼重要的地位。
首先要先了解一下什麼是MCU?這是一種發展了四十多年的技術,它將運算單元(CPU)、輸出入單元(GPIO)、輔助控制單元(Timer, UART, I2C, SPI, ADC等)及記憶體(Flash, SRAM, EEPROM)整合在同一顆晶片上,相當於把一部電腦塞進一個晶片中,故早期亦將MCU稱為「微電腦晶片」。近年來更有許多廠商把無線通訊部份(如WiFi, BlueTooth, Zeebee, 4G, 5G等)甚至人工智慧所需的神經運算加速單元(如NPU)加入其中。
MCU的優點是體積小、價格便宜(視功能配置,約US$ 0.5 ~ 20)、功耗極低(mW等級)可使用電池供電、功能強大,從4bit到32bit都有,容易開發,有非常完整的工具鏈(Tool Chain)及生態體系(Ecosystem),連中小學生在玩的Micro:bit, Arduino開發板都屬於MCU的範圍。但缺點是系統架構種類及供應商太多,沒有統一的開發工具。
另外受限價格因素,通常工作時脈不高(MHz等級),程式及記憶體區域都很小(KByte等級,少數能到MByte),不利大量運算,通常也沒有作業系統,僅有少數像Arm Mbed, RTOS能運行在較高階的MCU上。所以開發出來的程式就很難像手機上的APP一樣可以任意運行在不同硬體的手機上。

Fig. 6-1 MCU依屬性主要分類方式。(OmniXRI整理繪製, 2021/9/9)
而MCU依不同屬性有不同的分類方式,如Fig. 6-1所示。以下就根據不同屬性作一簡單說明。
依「工作用途」可分為使用者可完全使用全部資源的「通用型MCU」,和有特定用途,僅需少量程式碼或完全不需使用者程式的「專用型MCU」,當然也有兩者混合的類型,端看面對的市場而定。
依「處理器結構」可分為馮紐曼結構(von Neumann architecture, 或譯為馮.諾依曼)和哈佛結構(Harvard architecture),前者中央處理器和儲存裝置分開且程式和資料儲存在同一個記憶體中,指令和資料不能同時存取,而後者的程式和資料則分開存放在不同的記憶體中,存取時各自有匯流排(Bus),可於同一週期中運行,處理速度較快。
依「指令集家族」又可分為複雜指令集(Complex Instruction Set Computer, CISC)和精簡指令集(Reduced Instruction Set Computer, RISC),前者主要代表有Intel 8051系列,而後者常見代表則有Arm Cortex-M, RISC-V, Atmel AVR, Microchip PIC, TI MSP430等系列,後者有指令工作週期短及省電優勢,因此目前在MCU領域RISC已逐漸取CISC。
依「指令寬度」可分為4/8/16/32 bit,部份廠商亦有依不同需求而採混合指令寬度,如Arm Cortex-M就有採用Thumb-1(16bit)和Thumb-2(32bit)的作法。
依「程式記憶體」可分為不帶(外掛)程式記憶體,由半導體廠直接光罩(MASK)製作(俗稱Read-Only Memory, ROM),使用者可一次燒錄的(One Time Programmable ROM, OTPROM),可重覆燒錄的紫外線抹除式可複寫唯讀記憶體(Erasable Programmable ROM, EPROM)或電子抹除式可複寫唯讀記憶體(Electrically-Erasable Programmable ROM, EEPROM)或NOR型快閃記憶體(Flash ROM)。而常用於記憶卡的NAND Flash雖然儲存容量很大,但由於存放資料不連續,難以直接用來儲存程式碼,如一定要用(如導入作業系統),則通常需要搭配大量的隨機記憶體(如SRAM, DRAM, DDR等)來使程式能連續存放於記憶體中。
接著就幫大家介紹一下tinyML最重要的推手「Arm Cortex-M MCU」家族。首先要認識一下安謀(Arm)這家公司,它是一家不生產實體積體電路(Integrated Circuit, IC)的公司,它只授權矽智財(Intellectual Property Core, IP)給其它公司整合成實體積體電路。1985年Arm推出第一顆RISC架構的CPU「Arm1」。2004年推出第一顆32bit RISC指令集的MCU IP 「Cortex-M3」,此後接連發展出Cortex-M (MCU)系列,包括M1, M0, M4, M0+, M7, M23, M33, M35P, M55等,有許多知名的廠商都有授權生產不同用途的MCU,如STM, NXP, TI等,國內亦有像新唐(NuvoTon)、盛群(Holtek)、松翰(Sonix)等廠商。
由於Cortex-M系列MCU規格跨度很大,對於不同的tinyML應用,我們需要對一些規格有一些基本認識,方便後續理解如何選用、效能分析及應用場合。在[Day 03]時,我們已提及工作時脈、程式碼和隨機記憶體的重要性。在[Day 05]也得知如果要使用深度學習卷積神經網路時會產非常巨量的運算需求。因此如果想要加速運算就需要考下列幾項因素。
更完整的Arm Cortex-M系列介紹,可參考Arm官方連結。
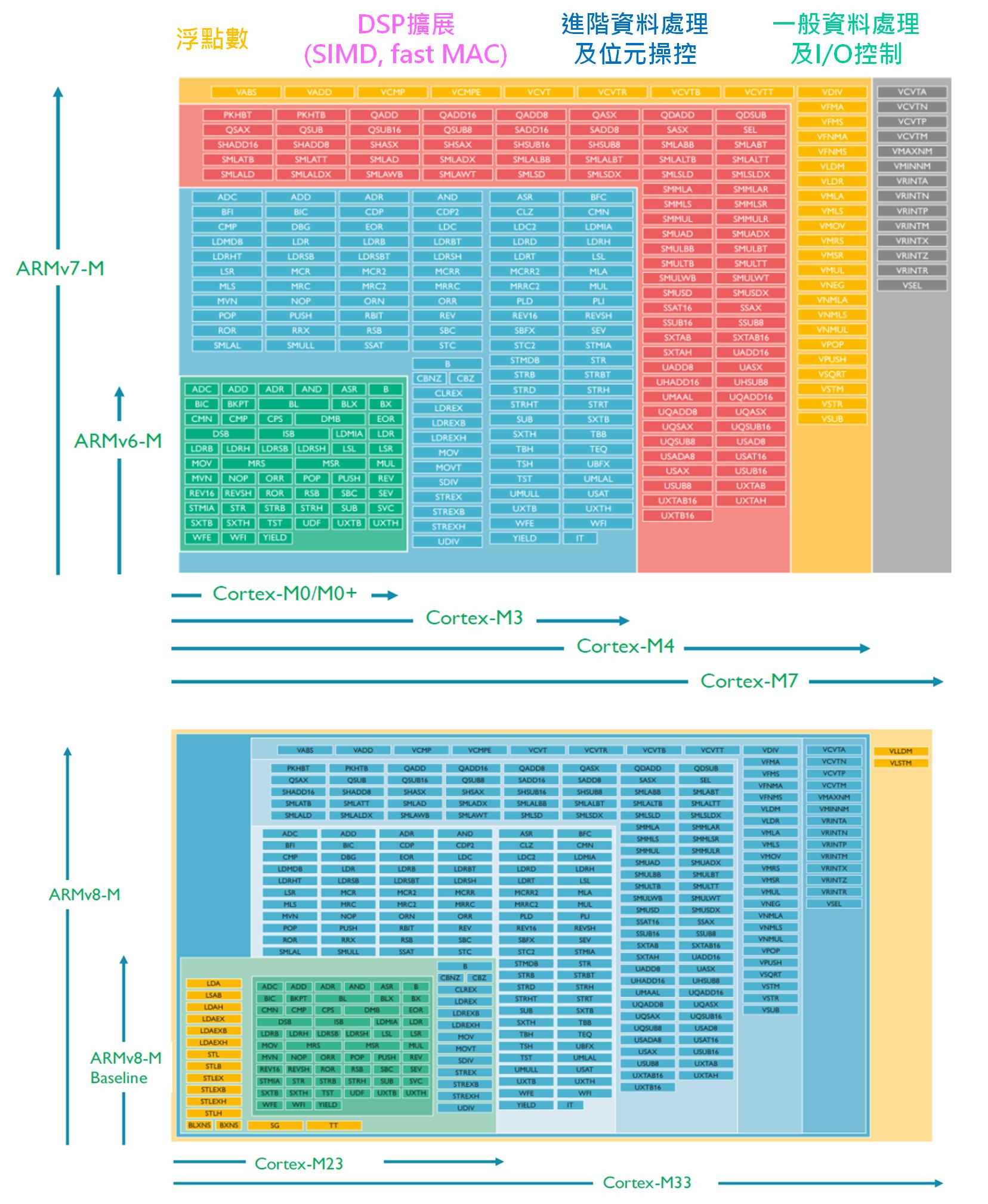
Fig. 6-2 Arm Cortex-M系列指令集一覽表。(資料來源:如文末參考資料二)
不管tinyML運行的是傳統機器學習(ML)、深度神經網路(DNN)或卷積神經網路(CNN),大量的矩陣(MAC, 乘加)計算都是免不了的,所以如果單指令就能完成一次乘加動作,就比起要分成一次乘法(多週期)和一次加法快上至少兩倍。若再加上單指令多資料流(Single Instruction Multiple Data, SIMD)指令,那就能讓一個32 bit的指令再分拆成2個 16bit或4個8bit整數指令運算,如此就能讓運算速度再提升2到4倍。如果不懂這些加速的程式如何撰寫或優化,則還可利用Arm提供的CMSIS(Common Microcontroller Software Interface Standard)函式庫來協助,這部份就留待後續章節再補充說明。
綜合上述硬體規格來看,似乎Cortex-M4剛好是一個一個分界點,它支援單週期乘加、浮點運算及SIMD指令集,相當於一個指令週期可發揮2~8倍甚至更高功效,同時配置有較大的程式碼和隨機記憶體區,不僅可以容納較大的神經網路模型和參數,亦可選擇性的佈署Arm Mbed作業系統,這對於後續tinyML的小型Edge AI應用程式開發有很大的幫助。至於M3以下的MCU就留給像智慧感測器等更小的應用了。
參考連結

